 Image credit: Unsplash
Image credit: Unsplash
Abstract
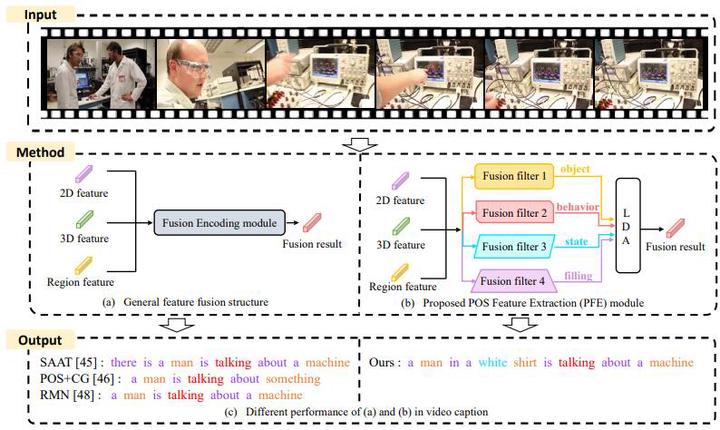
Video caption aims to generate descriptive sentences about the video, and the most critical problem is how to achieve accurate word prediction with standardized and coherent syntax structure, which requires the model to thoroughly understand video content and precisely map them into corresponding sentence components. Many existing methods usually fuse different video features into a single visual feature for generating sentences. However, they ignore the word dataset prior information in the annotations (such as Part-Of-Speech) and they also ignore the association between sentence components and types of visual features. To solve these problems, we propose a POS-trends dynamic-aware model (PDA) to fully exploit the word dataset prior information in the captions to predict POS tag, so as to assist generating captions. We propose a POS feature extraction (PFE) module to use different filters to extract different POS-trends features, predict POS tags and fuse visual features. Furthermore, we propose a visual-dynamic-aware (VDA) module to dynamically adjust the mapping way of words and supplement the visual information into the local features. The fusion features provide directional visual information to generate correct words, and the predicted POS tags to guide the decoding process to generate a more standardized and coherent syntax structure. A large number of experiments based on MSVD, MSR-VTT and VATEX demonstrated that our method outperforms the state-of-the-art methods in BLEU-4, ROUGE-L, METEOR, CIDEr.
Heqian Qiu
Ph.D Student
My research interests include object detection, multimodal representative learning, computer vision and machine learning.