Multi-stage Tag Guidance Network in Video Caption
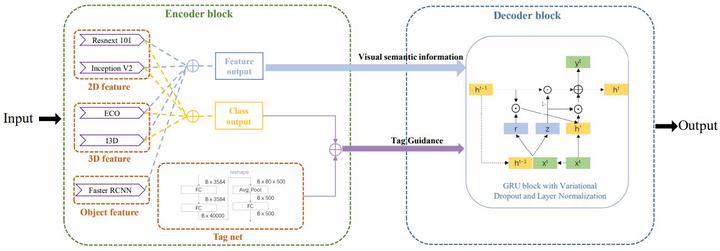 Image credit: Unsplash
Image credit: Unsplash
Abstract
Recently, video caption plays an important role in computer vision tasks. We participate in Pre-training for Video Captioning Challenge which aims to produce at least one sentence for each challenge video based on the pretraining models. In this work, we propose a tag guidance module to learn a representation which can better build the interaction in cross-modal between visual content and textual sentences. First, we utilize three types of features extraction networks to fully capture the information of 2D, 3D and object information. Second, to prevent overfitting and time issues, the entire process of training is divided into two stages. The first stage trains all data, and the second stage introduces a random dropout. Furthermore, we train a CNN-based network to pick out the best candidate results. In summary, we were ranked third place in Pre-training for Video Captioning Challenge which proved the effectiveness of our model.
Heqian Qiu
Ph.D Student
My research interests include object detection, multimodal representative learning, computer vision and machine learning.