A multi-scale language embedding network for proposal-free referring expression comprehension
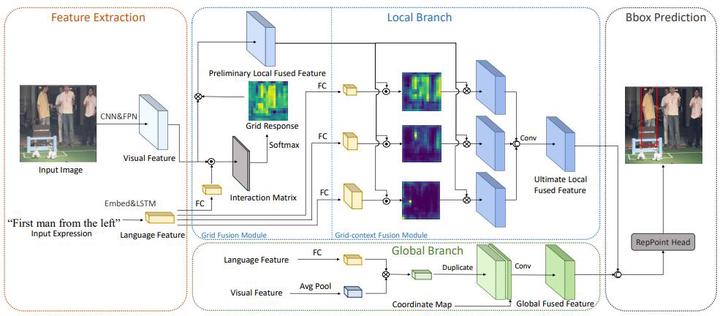 Image credit: Unsplash
Image credit: Unsplash
Abstract
Referring expression comprehension (REC) is a task that aims to find the location of an object specified by a language expression. Current solutions for REC can be classified into proposal-based methods and proposal-free methods. Proposal-free methods are popular recently because of its flexibility and lightness. Nevertheless, existing proposal-free works give little consideration to visual context. As REC is a context sensitive task, it is hard for current proposal-free methods to comprehend expressions that describe objects by the relative position with surrounding things. In this paper, we propose a multi-scale language embedding network for REC. Our method adopts the proposal-free structure, which directly feeds fused visual-language features into a detection head to predict the bounding box of the target. In the fusion process, we propose a grid fusion module and a grid-context fusion module to compute the similarity between language features and visual features in different size regions. Meanwhile, we extra add fully interacted vision-language information and position information to strength the feature fusion. This novel fusion strategy can help to utilize context flexibly therefore the network can deal with varied expressions, especially expressions that describe objects by things around. Our proposed method outperforms the state-of-the-art methods on Refcoco, Refcoco+ and Refcocog datasets.
Heqian Qiu
Ph.D Student
My research interests include object detection, multimodal representative learning, computer vision and machine learning.