Language-Aware Fine-Grained Object Representation for Referring Expression Comprehension
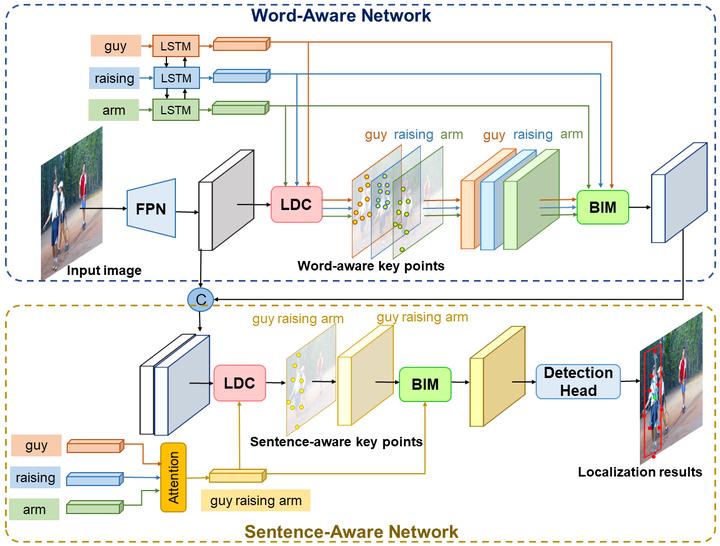 Image credit: Unsplash
Image credit: Unsplash
Abstract
Referring expression comprehension expects to accurately locate an object described by a language expression, which requires precise language-aware visual object representations. However, existing methods usually use rectangular object representations, such as object proposal regions and grid regions. They ignore some fine-grained object information like shapes and poses, which are often described in language expressions and important to localize objects. Additionally, rectangular object regions usually contain background contents and irrelevant foreground features, which also decrease the localization performance. To address these problems, we propose a language-aware deformable convolution model (LDC) to learn language-aware fine-grained object representations. Rather than extracting rectangular object representations, LDC adaptively samples a set of key points based on the image and language to represent objects. This type of object representations can capture more fine-grained object information (e.g., shapes and poses) and suppress noises in accordance with language and thus, boosts the object localization performance. Based on the language-aware fine-grained object representation, we next design a bidirectional interaction model (BIM) that leverages a modified co-attention mechanism to build cross-modal bidirectional interactions to further improve the language and object representations. Furthermore, we propose a hierarchical fine-grained representation network (HFRN) to learn language-aware fine-grained object representations and cross-modal bidirectional interactions at local word level and global sentence level, respectively. Our proposed method outperforms the state-of-the-art methods on the RefCOCO, RefCOCO+ and RefCOCOg datasets.
Heqian Qiu
Ph.D Student
My research interests include object detection, multimodal representative learning, computer vision and machine learning.